De færreste virksomheder har i dag taget stilling til brugen af syntetisk data, men det bør de. For om blot få år vil størstedelen af erhvervslivet benytte det.
Det globale marked for syntetisk data omsatte i 2021 for ”blot” 881,6 mio. kr. Men med forventede vækstrater på over 30% hvert eneste år fremover, og en forventet markedsstørrelse på 12,8 mia. kr. allerede i 2030, er det her et af de største fremtidige vækstmarkeder inden for it. Den forventede succes skyldes i høj grad, at syntetisk data giver virksomheder og offentlige myndigheder helt nye, hurtigere og billigere muligheder for at arbejde med kunstig intelligens og data end tidligere. Faktisk forventer Gartner, at 60% al data, der bruges til at udvikle AI’er og i analyseprojekter, vil være syntetisk allerede i 2024. En helt enorm udbredelse på ganske få år.
Hvad er syntetisk data?
Helt kort forklaret består syntetisk data af rent computergenerede datapunkter, der skabes som alternativ til data fra den virkelige verden. Syntetisk data bruges hovedsageligt, hvis ens eksisterende datasæt ikke er gode nok, og man derfor har behov for at skabe flere data, eller hvis man har personfølsomme og sensitive data, man gerne vil beskytte.
”Man kan f.eks. erstatte patientdata med ren syntetisk data, så man ikke risikerer at kunne identificere den enkelte patient og komme på kant med GDPR-lovgivningen. Eller hvis man kun har få tusinde datapunkter, kan man via syntetisk data skabe flere hundrede tusinde nye datapunkter, og på den måde lave bedre analyser eller træne sin AI mere effektivt,” fortæller Casper Guldager, senior manager i KPMG NewTech.
Sådan skaber du syntetisk data
Syntetisk data dannes altid på baggrund af data fra den virkelige verden. Med udgangspunkt i realdata, finder man en række tendenslinjer og sammenhænge, som man så kan skabe en lang række nye syntetiske datapunkter ud fra. Når man har skabt nok syntetiske datapunkter, fjerner man de oprindelige realdata, så der kun er de syntetiske tilbage. Og det er så dem, man arbejder med fremadrettet. Har man f.eks. en AI, der har brug for en masse data for at kunne blive præcis, kan det være et problem, hvis man kun har data fra 1.000 virkelige personer. Men ved at sørge for at sammenhængen i de syntetisk data er de samme som i de virkelige data, kan man relativt hurtigt skabe data fra 100.000 virtuelle personer, som AI’en så kan træne på. Casper Guldager understreger dog, at man sjældent får lige så gode data, som med data fra den virkelige verden.
”Syntetisk data vil næsten altid give et lidt dårligere resultater end virkelige data. Men hvis alternativet er intet datagrundlag, kan det være det rigtige alternativ. Specielt fordi man relativt hurtigt kan komme i gang med sin AI-træning eller analyse, og dermed få brugbare resultater.”
Forskellige metoder til at skabe syntetisk data
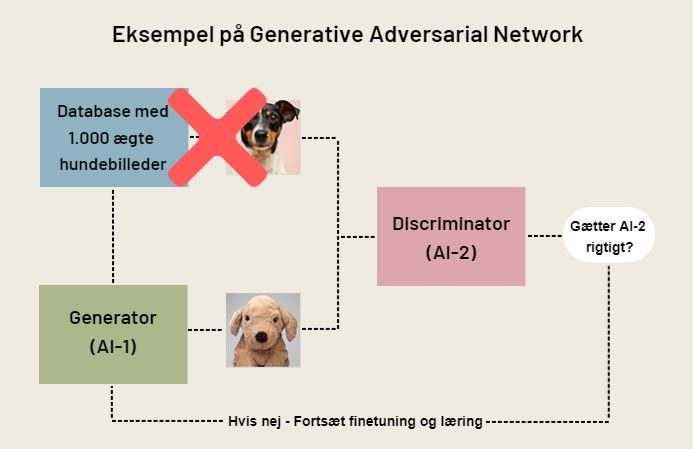
Der findes en række forskellige metoder til at skabe syntetisk data på. Den meste brugte er Generative Adversarial Networks (GAN), som oftest bruges i forbindelse med AI-træning samt til billede- og tekstanalyser. Et GAN består grundlæggende af to AI’er med modstridende interesser, som hjælpes ad til at blive bedre til en opgave. Forestil dig, at du gerne vil have en AI til at kunne genkende hunde på billeder, men at du kun har 1.000 ægte hundebilleder at træne den med. Det vil typisk være for lidt, da en AI ofte har brug for mindst 100.000 hundebilleder at træne på, før den bliver dygtig nok. Det første man gør, er derfor at sætte en kunstig intelligens, AI-1, til at generere nye syntetisk skabte hundebilleder på baggrund af de 1.000 ægte hundebilleder.
Derefter sætter man en anden kunstig intelligens, AI-2, til at gætte, om der er tale om et reelt hundebillede eller et syntetisk skabt hundebillede. Så AI-1s job er altså at prøve at snyde AI-2 til at godkende falske hundebilleder, mens AI-2s job er at opdage de falske billeder. Når AI-1 er blevet så god til at skabe syntetiske hundebilleder, at AI-2 ikke længere kan se forskel, fjerner man de oprindelige 1.000 hundebilleder, og arbejder nu kun med syntetisk skabte billeder, fordi de er blevet så gode, at de ikke kan skelnes fra de rigtige. Det samme princip kan bruges i forhold til patientdata, billedgenkendelse og tekstanalyse o. lign., hvor man sikrer, at man analysemæssigt arbejder med valide (men kunstige) data, og samtidig ikke går på kompromis med privacy- og GDPR-lovgivningen.
Markedet for syntetisk data er stort
Allerede i dag ser man syntetisk data brugt flere steder i sundhedssektoren, da det i høj grad kan bruges i forbindelse med statistik og forskning. Men også indenfor militæret og forsvaret, er man langt fremme, når det gælder brugen af syntetisk data. Transport og logistik er et tredje område, som også så småt er ved at komme i gang, da der ligger et stort potentiale i at bruge syntetisk data til simuleringer og indsamling af data – f.eks. fra selvkørende biler, hvor man ikke ønsker at kunne identificere den enkelte kundes kørsel, men stadig har brug for dennes data til at gøre bilen mere sikker i sin kørsel og beslutninger.
Predictive maintenance og produktionsoptimering er andre steder, hvor det også er oplagt at benytte kunstigt fremstillede data til at forudse, hvornår det er optimalt at udskifte eller reparere ting. BMW har f.eks. brugt syntetisk data til at optimere deres processer i forhold til deres fabriksproduktion af biler.
Sådan kommer du i gang med syntetisk data
For at kunne skabe syntetiske data, skal du først og fremmest have adgang til reelle data i et vidst omfang.
”Når vi er ude og rådgive kunder om brugen af syntetisk data, anbefaler vi, at man som minimum har 1.000 datapunkter fra den virkelige verden, før man går i gang. Ellers bliver datamodellerne for svage og risikoen for skævheder og fejlfortolkninger for store,” udtaler Casper Guldager.
Derefter skal man bygge sin datamodeller op og løbende tjekke datakvaliteten, så man til sidst kan fjerne realdata, uden at det går ud over validiteten i ens analyser eller AI-træning. Selve træningen og udarbejdelsen af det syntetiske datasæt tager, alt efter hvor struktureret virksomhedens data er til at starte med, typisk 3-6 måneder. Når man er færdig og har opbygget et brugbart syntetisk datasæt, skal dette integreres i virksomhedens standardsystemer, så det kan bruges i dagligdagen. Men så er man også oppe at køre.